正規表現練習用ページへのアクセス
『言語研究のための正規表現によるコーパス検索』(大名力著,ひつじ書房) 3章及び4章のためのページです。次の「正規表現練習用ページに進む」をクリックすると,練習用ページに移動します。
「正規表現練習用ページ」に進む
練習用ページをダウンロードして使用する場合には,次のアーカイブファイルをご利用ください。
「正規表現練習用ページ」アーカイブファイル (ver. 1.0)
ファイルはZIP形式でアーカイブされています。ZIPファイルの展開方法については,サーチエンジンで「zip 解凍方法」「zip 展開方法」などと指定して検索すれば,方法を説明したページが見つかりますので,そちらでご確認ください。
本練習用ページ及びアーカイブファイルは『言語研究のための正規表現によるコーパス検索』の本文に沿って使用してください。ひつじ書房及び作者 (大名力) は動作や使用方法に関するサポートはいたしません。
現在わかっている不具合:Windows の Internet Explorer では,[正規表現を選択して挿入]メニューから正規表現を選択する際,最初の操作では正規表現入力欄に正規表現が挿入されません。ページが表示された後,まずは正規表現入力欄をクリックし「ここに正規表現を入力します」の文字列をクリアしてからご使用いただくよう,お願いいたします。 なお,Firefox では上記不具合は生じません。
2012/09/07
電子書籍化にあたっての補足
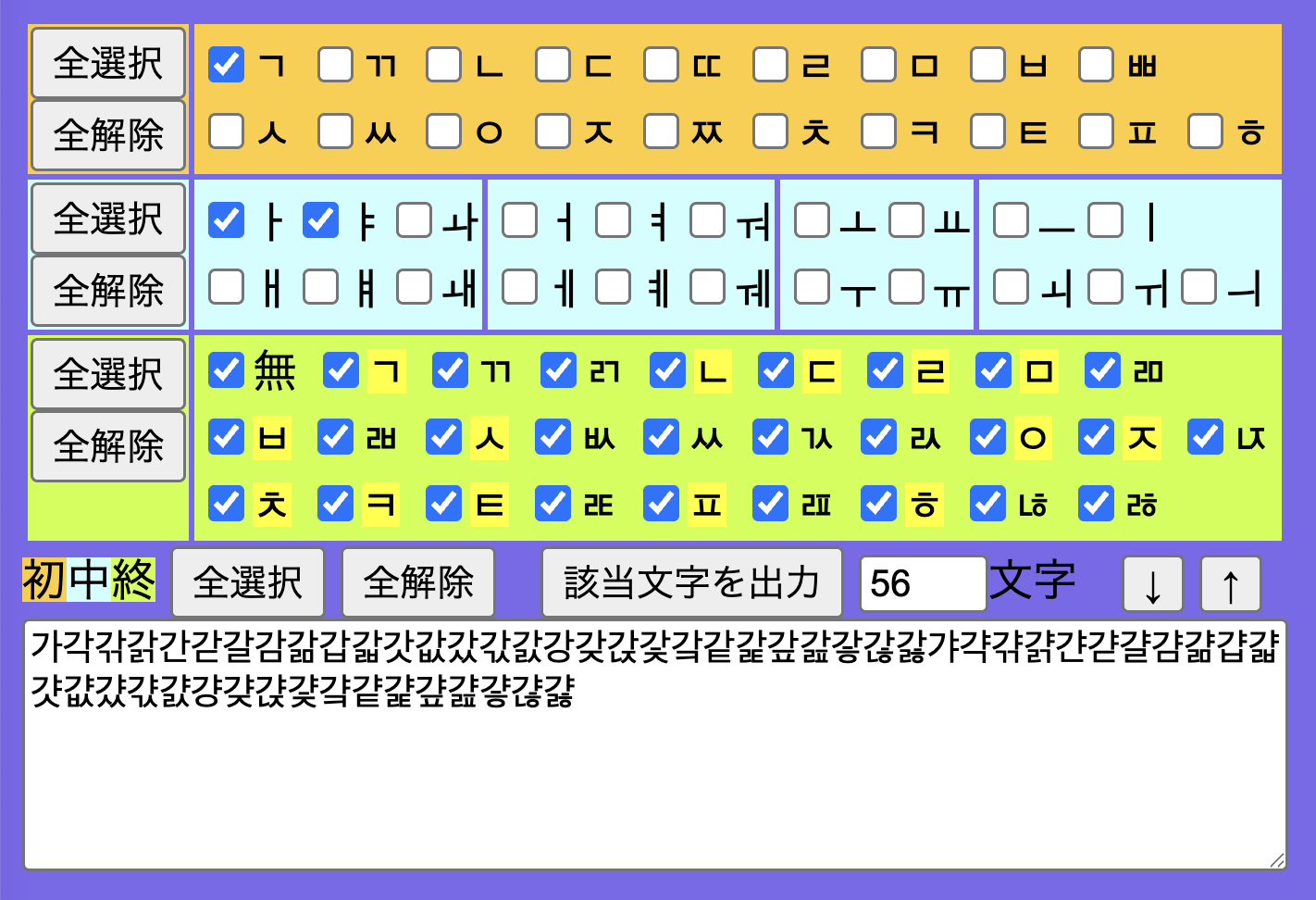
■p. 164の次の機能が利用できるサイト,ページは現在ではサーバーが停止しているため利用できない。
A. 共通の字母を持つハングルをリストする
B. 指定の字母を含むハングルをリストする
同様の処理が行えるウェブページをこちらに置いたので,必要な方はご利用いただきたい。
https://www.hituzi.co.jp/560regex/kybd4ko.html
使い方:初声・中声・終声ごとに字母を選択 (「全選択」「全解除」ボタンですべてを選択・解除),「該当文字を出力」で下部の欄に文字の一覧を出力。
■CJK統合漢字1字にマッチする文字クラス
本書では漢字1字 (CJK統合漢字) にマッチする文字クラスを 1 または 2 としているが,「龥」と「龻」の違いは Unicode のバージョンの違いに依る。
1. [一-龥]
2. [一-龻]
3. [一-鿿]
Unicode 1.1 では「龥」(U+9FA5) までが定義されていたが,2005年リリースの Unicode 4.1 で「龦」(U+9FA6) 〜「龻」(U+9FBB) が追加された。

現在では「龻」より後の部分 (「龼」(U+9FBC) 〜「鿿」(U+9FFF)) もすべて定義されているので,この部分も含めるには 3 のように指定する。
2026/03/16